안드로이드 기본개념 면접대비 정리

안드로이드가 나온지도 10년이 지났다.
우리나라에 막 나타나기 시작한 것이 2009년 쯤이니..
아직도 스마트폰은 안드로이드가 우세다.
아이폰 OS를 제외하면 견줄 것이 없다.
구글의 무서움은 모바일폰에서 그치지 않는다.
LTE, WiFi, Bluetooth 등을 활용한 무선통신이 가능한 기기들
모두의 시장을 점유하기 위해, 즉 IoT 시장을 차지하기 위한
다양한 용도의 OS들을 만들어가고 있다.
어찌되었든 아직까지도 기본은 안드로이드로 시작한다.
안드로이드는 리눅스를 기반으로해서 C, C++, Java 등
다양한 언어를 활용해 구성되어있는 플랫폼이다.
WiFi, LCD, LTE 등 다양한 HW를 구동시키는 드라이버단,
그 위에 이를 컨트롤하는 Hal단,
그 위에 이를 컨트롤하는 Framework단
그 위에서 움직이는 다양한 App과 Service 들...
너무나 방대하기에 이 플랫폼을 활용하는 것도
그때 그때 찾아보고 공부하지 않으면 힘이 든다.
구글은 이렇게 방대한 플랫폼을 오픈형으로 키웠고
이러한 생태계를 형성함으로써
IT 시장의 점유율을 높인 무서운 정책을 펼친 회사다.
각설하고...
안드로이드를 활용한 취업시장은
아직 유효할 듯 하다는 것이 포인트!!
이러한 안드로이드를 조금 안다고 면접장에서 방귀를 끼려면
아래에 정리한 것들을 참고하시라.
어디서 본 정보를 취합하고 내 생각도 더한 자료 이다.
보충이 필요한 부분은 댓글로 언제나 환영이다.
Q0. 안드로이드의 실행환경에 대해서 간단하게 설명하시오.
안드로이드는 크게 4가지 실행환경으로 구성되어있습니다. 가장 하단부터 리눅스 커널, 라이브러리, 어플리케이션 프레임워크, 어플리케이션 순서입니다. 리눅스 커널은 OS로 안드로이드 스마트폰의 다양한 하드웨어(화면, 카메라, 블루투스, GPS, 메모리 등)를 관리합니다. 라이브러리는 안드로이드에 있는 다양한 기능(UI 처리, 미디어 프레임워크, 데이터베이스, 그래픽 처리, 웹 킷 등)을 소프트웨어적으로 구현해 놓은 환경 뿐만 아니라 안드로이드 앱을 구동해주는 dalvik 가상머신과 코어 라이브러리까지 포함하는 영역입니다. 어플리케이션 프레임워크는 사용자의 입력(액티비티, 윈도우, 컨텐츠, 뷰, 노티피케이션 등) 또는 특정한 이벤트에 따라 출력을 담당하는 환경을 말합니다. 마지막으로 실제로 동작하는 앱이 설치되는 환경인 어플리케이션이 있습니다.
Q1. 안드로이드는 다른 플랫폼에 비해 어떤 장점이 있는가?
첫째로 안드로이드를 구성하는 모든 소스가 오픈소스로 무료로 개방되어있어 비용적인 부담이 없습니다. 또한 전 세계의 수많은 개발자로부터 피드백을 받아 수정되기 때문에 안정성과 버그 수정이 빠릅니다. 그 밖에도 원한다면 소스를 다운 받아 수정해서 쓰기 편리합니다. 둘째로 자바를 주 언어로 사용하고 있기 때문에 많은 세계적으로 점유율이 높은 자바 개발자들이 쉽게 개발할 수 있습니다. 셋째로 리눅스 커널을 OS로 채택했기 때문에 다양한 하드웨어에 대한 드라이버 소스가 풍부합니다. 마지막으로 구글의 다양한 앱과 연동이 매우 편리하며 다른 플랫폼에 비해 앱간 연동에 너그러운편입니다.
Q2. 안드로이드 프로젝트 구성요소에 대해서 설명하시오.
libs : 프로젝트에서 사용하는 다양한 라이브러리 소스가 저장되는 공간입니다.
androidTest : 앱의 일부 코드를 테스트하기 위한 소스를 저장하는 공간입니다.
java : 자바 코드를 저장하는 공간입니다. 표준 자바와 동일하게 패키지를 이용한 하위 디렉토리 생성 방식을 사용합니다.
res : 리소스(이미지, xml 레이아웃, 메뉴, 값)를 저장하는 공간입니다.
AndroidManifest.xml : 앱에 대한 전체적인 정보를 담고있는 파일입니다. 앱의 구성요소와 실행 권한 정보가 정의되어있습니다.
project > build.gradle : 프로그래머가 직접 작성한 그래들 빌드 스크립트 파일입니다.
gradle > build.gradle : 앱에 대한 컴파일 버전정보, 의존성 프로젝트에 대한 정의가 되어있는 파일입니다.
Q3. 안드로이드에서 다국어 지원을 위해 해야할 작업에 대해서 설명하시오.
다국어 지원을 위해서는 value resource file을 따로 생성해주는 방식으로 사용합니다.
'values > 마우스 오른쪽 버튼 클릭 > value resource file > 리소스 파일 이름을 strings로 입력 > available qualifiers 탭에서 locale 선택 > language 탭에서 언어 선택 > specific region only에서 세부 국가 선택'
파일을 생성하면 디렉토리의 이름은 values-국가코드(예를 들어 values-kr) 형식으로 생성되며 내부에 strings.xml 파일이 생성됩니다. 해당 파일에 string의 name 값은 동일하게 유지한 후 해당 국가의 언어로 번역하여 추가하면됩니다.
Q4. 안드로이드 매니페스트(android manifest) 파일에 대해서 설명하시오.
안드로이드 매니페스트는 앱의 이름, 버전, 구성요소, 권한 등 앱의 실행에 있어서 필요한 각종 정보가 저장되어있는 파일입니다. 반드시 존재해야하는 xml 형식의 파일로 안드로이드 프로젝트의 최상위에 위치하고 있습니다.
가장 최상위는 manifest 태그가 위치하고 있습니다. manifest 태그에는 패키지명, 앱 버전 코드, 앱 버전 이름을 정의합니다.
application 태그에는 앱 아이콘, 앱 이름을 정의합니다.
activity 태그에는 액티비티의 클래스명과 액티비티 이름을 정의합니다. 하위에는 intent-filter 태그를 이용하여 액티비티에 대한 인텐트 작업시 필요한 action과 category를 정의합니다.
service, receiver, provider 태그에는 각각 서비스, 리시버, 프로바이더에 대한 내용을 정의합니다.
permission 태그에는 앱에서 필요한 권한에 내용을 정의합니다.
그 밖에 최소 안드로이드 SDK 버전을 지정하는 uses-sdk와 다른 패키지를 등록할 수 있는 uses-library 태그 등이 존재합니다.
Q5. 디스플레이(display), 윈도우(window), 서피스(surface), 뷰(view), 뷰 그룹(view group), 뷰 컨테이너(view container), 레이아웃(layout)에 대해서 설명하시오.
디스플레이 : 안드로이드 단말기가 가지고 있는 하드웨어 화면을 의미합니다.
윈도우 : 안드로이드에서 실행되는 앱이 그림(뷰)을 그릴 수 있는 영역을 의미합니다. 사용자로부터 입력(터치, 키) 이벤트를 받아 앱에 전달합니다.
서피스 : 윈도우에 그림(뷰)을 그릴 때 그림이 저장되는 메모리 버퍼를 의미합니다.
뷰 : 사용자 인터페이스를 구성하는 최상위 클래스를 말합니다. 윈도우의 서피스를 이용하여 화면에 어떤 모양으로 그림을 그릴지와 발생하는 이벤트를 어떻게 처리할 것인지에 대한 기능을 구현하고 있습니다. 뷰 중에서 일반적인 제어 역할을 하고 있는 것들을 위젯이라고 합니다.
뷰 그룹 : 여러개의 뷰를 포함하고 있는 뷰를 의미합니다.
뷰 컨테이너 : 다른 뷰를 포함할 수 있는 뷰를 의미합니다. 대표적으로 리스트 뷰(list view), 스크롤 뷰(scroll view), 그리드 뷰(grid view) 등이 있습니다.
레이아웃 : 뷰 그룹 중에서 내부에 뷰를 포함하고 있으면서 해당 뷰를 어떻게 윈도우에 배치할지 정의하는 관리자 역할을 하는 클래스 말합니다.
Q6. 인플레이션(inflation)이란 무엇인가?
xml 레이아웃 파일로 정의한 정보를 런타임에 setContentView 메소드가 호출됨에 따라 메모리 상에 객체로 만들어주는 과정을 말합니다. 이 과정에서 xml 레이아웃 파일에서 뷰에 id를 설정하고 해당 id가 R.java 파일에 주소 값으로 환원되며 findViewById 메소드와 id를 이용하여 코드 상으로 뷰 객체를 가져와 제어할 수 있습니다.
Q7. 안드로이드에서 색상을 지정하는 다양한 방식은 어떤 것들이 있는가?
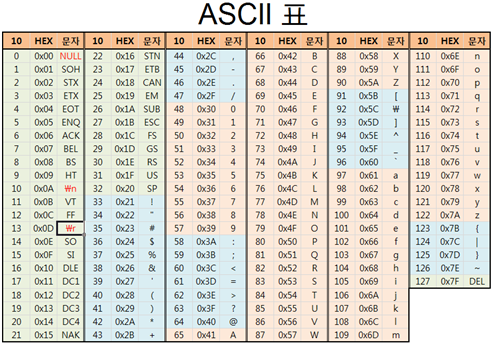
#RGB, #ARGB, #RRGGBB, #AARRGGBB 총 4가지 방식이 있습니다. R은 붉은색, G는 초록색, B는 파란색의 정도를 나타내며 A는 알파 값 즉 투명도를 나타내는 수치입니다. 각각의 요소는 16진수(0부터 F까지)로 표현합니다.
Q8. 안드로이드의 크기를 표현하는 다양한 표현방법에 대해서 설명하시오.
픽셀(px) : 화면의 픽셀을 의미합니다.
밀도 독립적 픽셀(dp, dip) : 160dpi(160인치에 들어가있는 픽셀 수) 화면을 기준으로 한 픽셀을 의미합니다.
축척 독립적 픽셀(sp, sip) : 가변 글꼴을 기준으로 한 픽셀을 의미합니다. 글꼴의 설정에 따라 차이가 있습니다.
텍스트 크기(em) : 글꼴과 상관없이 동일한 텍스트 크기를 표시하기 위한 단위입니다.
그 외 인치(in), 밀리미터(mm)가 있습니다.
Q9. 안드로이드의 4대 컴포넌트(component)에 대해서 간단하게 설명하시오.
안드로이드의 4대 컴포넌트는 액티비티, 서비스, 브로드캐스트 리시버, 콘텐트 프로바이더입니다. 첫 번째로 액티비티는 안드로이드에서 화면을 관리하고 사용자가 발생시키는 다양한 이벤트를 처리하는 컴포넌트입니다. 두 번째로 서비스는 화면에서 보이지 않지만 특정한 기능을 백그라운드에서 수행하는 컴포넌트입니다. 세 번째로 브로드캐스트 리시버는 특정 안드로이드에서 발생하는 특정 브로드캐스트 메세지를 처리하기 위한 컴포넌트입니다. 네 번째로 콘텐트 프로바이더는 앱간 데이터의 공유를 위해 표준화된 인터페이스를 제공하는 컴포넌트입니다.
Q10. 안드로이드 MVC 모델은 어떻게 구성되어있는가?
안드로이드에서 뷰는 화면에 실제로 보이는 구성을 만드는 영역으로 View 클래스를 상속하는 클래스를 이용하여 구성할 수 있습니다. 다음으로 컨트롤러는 뷰와 모델을 서로 연결하며 제어하는 영역으로 액티비티, 서비스, 브로드캐스트 리시버, 프래그먼트로 구성됩니다. 마지막으로 모델은 앱의 다양한 데이터를 저장하는 역할로 SQLite를 이용한 DB, SharedPreference를 이용한 파일 시스템, 콘텐트 프로바이더가 있습니다.
Q11. 액티비티(activity)가 무엇인지와 액티비티 생명주기에 대해서 설명하시오.
안도르이드에서 화면을 관리하며 사용자가 발생시키는 다양한 이벤트를 처리하는 컴포넌트입니다.
부모 액티비티에서 새로운 자식 액티비티를 실행하고자 한다면 먼저 매니페스트 파일에 해당 자식 액티비티를 추가 해줘야합니다. 다음으로 부모 액티비티에서 startActivity 메소드에 인텐트를 파라미터로 넘겨 실행하거나 startActivities 메소드를 이용하여 여러개의 액티비티를 한꺼번에 실행할 수 있습니다.
액티비티의 실행과정은 첫 번째로 부모 액티비티에서 자식 액티비티를 생성 및 호출합니다. 두 번째로 액티비티 매니저 서비스가 해당 앱 프로세스에서 인텐트를 복사해온 후 매니페스트 파일에서 해당 인텐트에 명시되어있는 액티비티를 찾고 어떻게 실행시켜야할지 결정합니다. 세 번째로 찾아낸 액티비티를 실행하고 다시 해당 앱 프로세스에 인텐트를 복사하여 넘겨줍니다. 그 외 자식 액티비티 내의 onCreate 메소드에서 setContentView 메소드에 레이아웃의 아이디를 파라미터로 넘겨 해당 액티비티의 화면을 구성하게됩니다.
액티비티는 크게 3가지 상태가 존재합니다. 먼저 실행(running) 상태는 액티비티 스택의 최상위에 있으며 포커스를 가지고 있어 사용자에게 보이는 상태입니다. 다음으로 일시 중지(paused) 상태는 사용자에게 보이기는 하지만 다른 액티비티가 위에 있어 포커스를 받지 못하는 상태를 말합니다. 예를들어 대화상자가 위에 있어 일부가 가려져 있는 경우를 말합니다. 마지막으로 중지 (stopped) 상태는 다른 액티비티에 의해 완전히 가려져 보이지 않는 상태를 말합니다.
액티비티가 처음 만들어지면 onCreate 메소드가 호출되어 레이아웃을 구성합니다. 이후 onStart 메소드가 화면에 보이기 직전에 호출됩니다. 다음으로 onResume 메소드가 사용자 상호작용(화면이 포커스를 얻었을 때)하기 바로 전에 호출됩니다. 이 3가지 메소드가 호출되어 액티비티는 실행 상태를 갖게됩니다. 이후 포커스를 잃었을 때 onPause 메소드가 호출되고 일시 중지 상태가 됩니다. 일시 중지 상태에서 다시 포커스를 획득하면 onResume 메소드가 호출되거나 다른 액티비티에 의해서 완전히 화면이 가려졌는지 여부를 확인하여 가려져 보이지 않는 경우 onStop 메소드가 호출되어 중지 상태가됩니다. 정지 상태에서 다시 화면이 보이기 직전에 onRestart 메소드가 호출되고 onStart 메소드가 차례로 호출됩니다. 그 외 finish 메소드가 실행되어 해당 액티비티가 종료되기 직전에 onDestroy 메소드가 실행됩니다.
가끔은 일시 중지나 중지 상태에서 시스템이 메모리가 부족하다고 판단될 경우 onCreate 메소드부터 다시 해당 액티비티를 구동합니다. 이 경우 onStop, onResume 메소드 호출이 생략됩니다. 따라서 onSaveInstanceState, onRestoreInstanceState 메소드를 이용하여 액티비티가 갑자기 죽을 것을 대비해서 상태를 저장하고 복원하기 위한 작업을 정의해줄 수 있습니다.
Q12. 액티비티간 데이터 전달에서 임의의 클래스 객체를 바로 전달하지 못하는 이유는 무엇이고 전달하기 위해서는 어떤 처리가 필요한가?
액티비티간 전달할 수 있는 데이터의 type은 보통 기본형으로 정해져있습니다. 그 이유는 인텐트를 이용하여 액티비티의 데이터를 전달하는 과정에서 현재 실행중인 앱 프로세스가 시스템 프로세스로 실행중인 액티비티 매니저 서비스 프로세스에게 인텐트를 전달합니다. 이 경우 프로세스간 통신이기 때문에 인텐트에 있는 값들을 복사하여 넘기는 방식으로 처리되기 때문에 객체 주소를 바로 넘기지 못하는 문제가 발생합니다. 따라서 이 문제를 해결하기 위해 자신이 임의로 만든 클래스 객체를 전달하기 위해서는 Serilizable이나 Parcelable 인터페이스를 상속받아 객체를 직렬화하여 넘기는 방식을 사용해야합니다.
Q13. 부모 액티비티에서 자식 액티비티의 결과 값을 받아오기 위해 어떻게 해야하는가?
먼저 부모 액티비티에서 startActivityForResult 메소드를 이용하여 인텐트와 리퀘스트 코드를 파라미터로 넘깁니다. 이후 자식 액티비티에서 setResult 메소드에 결과 코드와 데이터를 파라미터로 넘깁니다. 다시 부모 액티비티에서 onActivityResult 메소드를 오버라이딩하여 자식 액티비티에서 보낸 결과 코드와 데이터를 받아 처리하는 코드를 작성할 수 있습니다. 이후 실행과정에서 자식 액티비티의 finish 메소드가 호출되면 부모 액티비티가 다시 화면에 나타나면서 onResume 메소드가 실행됩니다. 이때 onActivityResult 메소드가 작동하게 됩니다.
Q14. 안드로이드가 리소스(resource)를 접근하는 방식에 대해서 설명하시오.
Q15. 서비스(service)가 무엇인지와 서비스 생명주기에 대해서 설명하시오.
서비스는 백그라운드에서 실행되는 구성 요소입니다. 서비스는 사용자에게 보이는 화면이 존재하지 않으며, 정해지지 않은 시간 동안 운영됩니다. 각각의 서비스는 매니페스트 파일에 서비스 태그를 이용하여 선언해야합니다. 서비스는 Service 클래스를 상속받아 onStartCommand 또는 onBind 메소드를 재정의하여 구현할 수 있습니다.
서비스는 다른 구성 요소들처럼 메인 쓰레드에서 동작합니다. 따라서 CPU를 많이 사용하거나 대기 상태를 필요로 하는 경우 새로운 쓰레드를 이용하여 생성해야합니다. 또한 서비스의 객체는 단말에서 오직 1개만 생성되어 관리합니다.
먼저 서비스가 startService 메소드로 실행되는 경우 서비스가 생성될 때 onCreate 메소드가 실행됩니다. 이후 서비스가 실행을 시작할 때 onStartCommand 메소드가 호출되며 서비스의 상태가 실행중으로 변경됩니다. 이후 stopService 메소드가 실행되면 서비스가 종료되며 onDestroy 메소드를 호출하며 서비스의 상태가 종료로 변경됩니다.
다음으로 서비스가 bindService 메소드로 실행되는 경우 서비스가 생성될 때 onBind 메소드가 호출됩니다. 다음으로 unbindService 메소드가 호출되어 바인딩이 해제되면 onUnbind 메소드가 호출됩니다. 이후 완전히 종료될 때 onDestroy 메소드가 호출됩니다.
Q16. 브로드캐스트 리시버(broadcast receiver)가 무엇인가?
Q18. 인텐트(intent)와 인텐트 필터(intent filter)에 대해서 설명하시오.
Intent : 어떤 Activity에 데이터를 보낼 때 값들을 지정하기 위해 사용
인텐트필터 : AndroidManifest.xml에서 설정하는 암시적 인텐트 (받는 쪽에서 설정 함)
즉, 인텐트를 보내는 앱에서는 받는 앱의 이름을 알 필요가 없다.
Q19. 어플리케이션(application)과 컨텍스트(context)에 대해서 설명하시오.
어플리케이션 앱 프로세스가 실행되면 가장 먼저 생성되는 객체로 하나의 어플리케이션 객체는 하나의 앱 프로세스와 대응됩니다. 앱이 백그라운드로 내려가도 앱 프로세스는 계속 살아있기 때문에 어플리케이션 객체도 살아있다고 할 수 있습니다.
컨텍스트는 안드로이드의 컴포넌트들이 동작하기 위해 필요한 정보를 담고 있는 객체를 말합니다. 각각의 컴포넌트들(액티비티, 서비스, 브로드캐스트 리시버 등)은 자신만의 컨텍스트를 가지고 있습니다. 컨텍스트 내에는 어플리케이션의 정보(패키지명 등), 컨텍스트가 실행되는데 필요한 정보(테마 등)를 얻거나 시스템 서비스(윈도우 매니저, 레이아웃 인플레이터 등)를 구동하는데 사용됩니다.
Q20. 노티피케이션(notification)은 무엇인가?
Q21. 안드로이드에서 로그(log)를 출력하는 방법과 종류를 설명하시오.
Q22. 스타일(style), 테마(theme)에 대해서 설명하시오.
Q23. 프레그먼트(fragment)가 와 프레그먼트 생명주기에 설명하시오.
프레그먼트는 액티비티의 일부분에만 배치되는 화면 및 동작을 조작하기 위한 객체입니다. 안드로이드 3.0(허니콤)에서 화면이 비교적 큰 태블릿의 등장으로 작은 단위의 화면의 생명주기 관리할 필요가 있어 추가되었습니다. 프레그먼트 매니저를 통해서 여러개의 프레그먼트를 조작할 수 있습니다. 레이아웃 xml 파일에서 다른 뷰들과 함께 배치될 수 있습니다.
액티비티가 생성되면 프레그먼트 매니저는 초기화(initializing) 상태가 됩니다. 프레그먼트가 매니저에 의해 추가되면 onAttach, onAttachFragment, onCreate 메소드가 차례로 실행됩니다. 다음으로 액티비티의 onCreate 메소드 호출 이후 매니저는 생성(created) 상태로 변경됩니다. 이때 onCreateView, onViewCreated, onActivityCreated 메소드가 차례로 호출됩니다. 다음으로 액티비티의 onStart 메소드가 호출되면 매니저는 시작(started) 상태로 onStart 메소드를 호출합니다. 이후 액티비티의 onResume 메소드가 호출되면 매니저 역시 재시작(resume) 상태로 변하며 onResume 메소드를 호출합니다. 그 외 액티비티가 화면에서 보이지 않을경우 호출되는 onStop 메소드 호출 이후 매니저는 중지(stop) 상태가 되며 액티비티의 onDestroy 메소드 호출 이후 매니저는 onDestroyView 메소드를 호출합니다.
Q24. 뷰 홀더 패턴(view holder pattern)에 대해서 설명하시오.
Q25. 나인패치(9patch)란 무엇인가?
Q26. 태스크(task)란 무엇인가?
예를들어 어떤 앱에서 앨범 앱을 실행하는 기능이 있다면 이 앱은 두개의 앱을 실행하는 형태가 되지만 사용자 입장에서는 하나의 앱에서 화면이 전환된다고 판단합니다. 이와 같은 사용자 입장에서 논리적인 화면 구성의 단위를 태스크라고 말합니다.
Q27. 안드로이드의 메모리 관리 방식에 대해서 설명하시오.
안드로이드는 액티비티, 서비스, 리시버, 프로바이더를 실행하기 위해 앱이 실행되는 과정에서 프로세스를 생성합니다. 실행중인 모든 앱은 컴포넌트가 모두 종료되어도 다음에 이 앱을 다시 실행할 가능성이 높기 때문에 프로세스를 바로 제거하지 않습니다. 바로 종료하지 않는 이유는 앱을 실행하기 위해 프로세스를 생성하는 과정에서 딜레이가 발생하는데 이 딜레이를 줄이기 위함입니다. 따라서 사용자에 의해 다시 앱이 실행되면 남아있던 프로세스가 존재하는 경우 바로 실행됩니다. 이 과정에서 쌓여있던 많은 프로세스로 인해 메모리가 부족해지는 경우 프로세스의 우선순위(사용빈도)에 따라 프로세스를 종료하여 메모리를 확보합니다.

'나는 프로그래머다! > Java & Android' 카테고리의 다른 글
| 안드로이드 개발 재개 from 2020 #2 구글플레이 등록 (0) | 2021.01.23 |
|---|---|
| 안드로이드 개발 재개 from 2020 #1 (0) | 2021.01.18 |
| Java 프로그램 jar를 exe로 만들기 (0) | 2019.10.01 |
| [안드로이드-API] Layout Traversal (0) | 2016.07.08 |
| [Java] String, StringBuffer, StringBuilder 차이 (0) | 2016.06.17 |
| [Java] Collection Framework 간단 정리 (0) | 2016.06.17 |
| 안드로이드 리소스 정책 #4 - 관리 및 방법 편 (0) | 2016.04.28 |
| 안드로이드 리소스 정책 #3 (0) | 2016.04.22 |
| 안드로이드 리소스 정책 #2 (0) | 2016.04.19 |
| 안드로이드 리소스 정책 #1 (0) | 2016.04.19 |


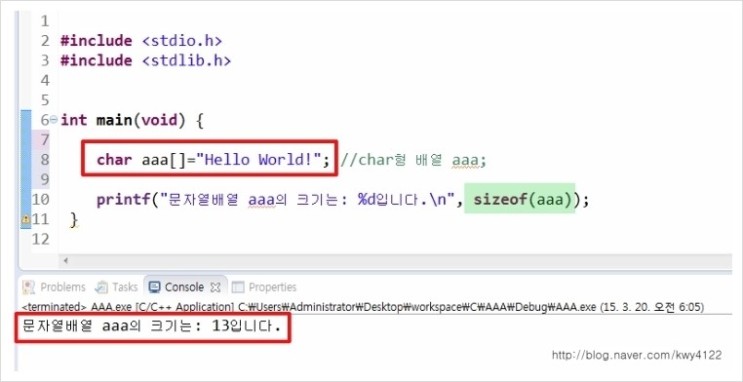
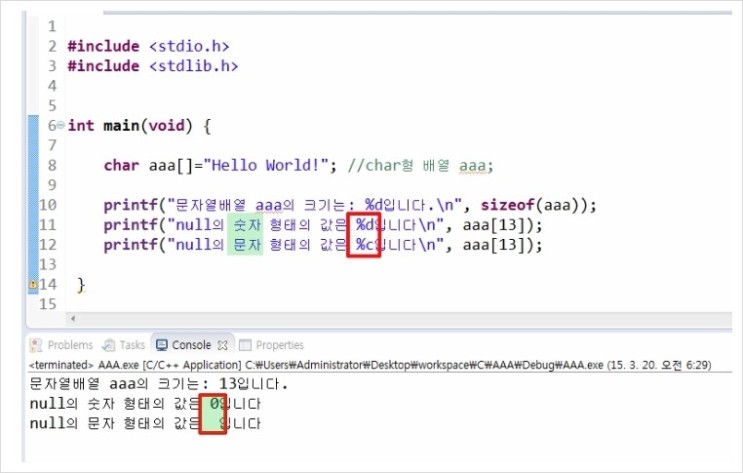
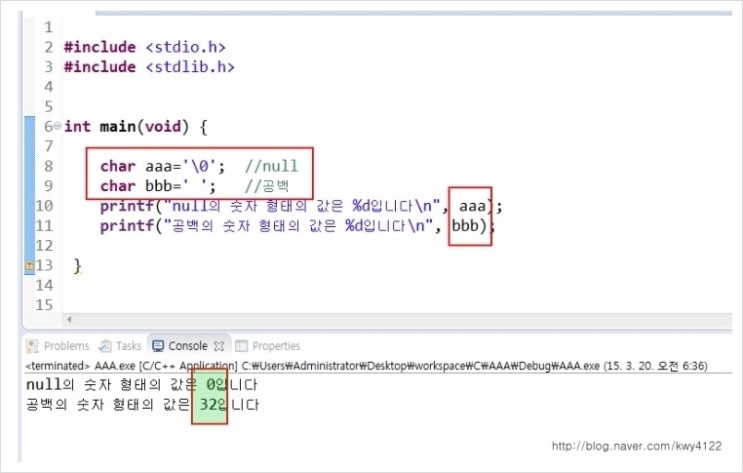


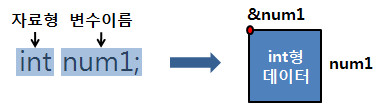


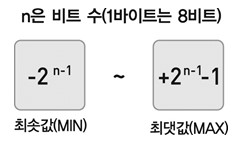

 ?
?




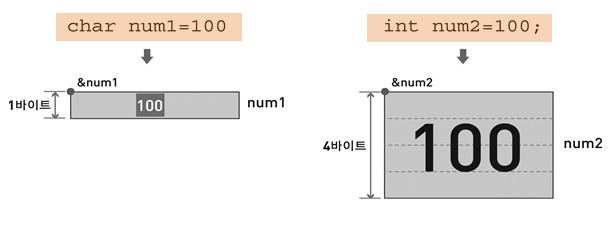

 ?
?



 ?
?






 ?
?




